- Xiaohan Ding,Honghao Chen,Xiangyu Zhang,Jungong Han,Guiguang Ding
- Beijing National Research Center for Information Science and Technology (BNRist)
- School of Software, Tsinghua University, Beijing, China
- Institute of Automation, Chinese Academy of Sciences
- MEGVII Technology
- Computer Science Department, Aberystwyth University, SY23 3FL, UK
- CVPR 2022
- Code
背景
卷积网络的成功中局部先验发挥着重要的作用,但是传统卷积网络无法很好的处理长距离依赖关系,只能通过加深网络结构缓解问题,而过深的网络导致最终特征图分辨率过小通道数过多反而不利于特征提取。为了解决卷积网络的长距离依赖问题,一些方法采用类似MLP的机制,因为对于全连接层(FC)来说可以获得任意两点之间的关系信息,但是MLP将特征图Flatten的做法会导致位置关系的丢失。
本文提出了RepMLPNet,其中通过Locality Injection的方法为FC引入位置信息,并且通过结构重参数化机制减少网络在推理时的参数量和计算量,增加推理速度。
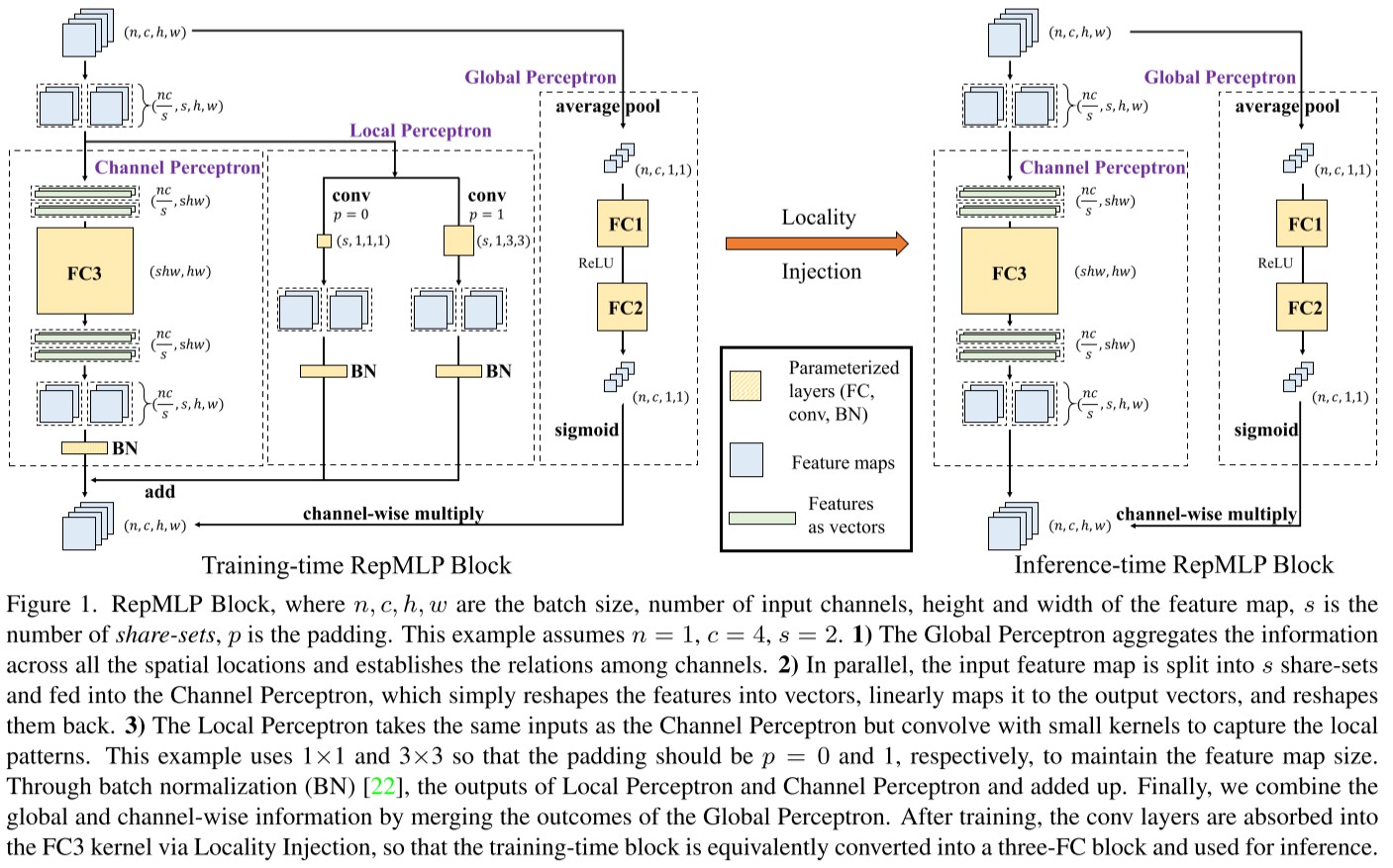
Method
经过重参数化的Locality Injection
基础公式表示
对于卷积操作,有张量
,其中 表示batch size, 为通道数, 为高度, 为宽度。使用 和 来表示卷积核和FC核。因此对于一个核为 的卷积运算来说有: 其中
, 为卷积输出通道, 指Padding大小, 为卷积核。 对于FC操作,输入维度为
,输出维度为 , 表示输入, 表示输出,FC核为 ,则有矩阵乘法(MMUL)公式: 假设FC以
作为输入, 作为输出,所以需要Reshape操作(缩写为RS)转换为向量,即 ,所以上述公式改写为:
Locality Injection
如图1所示,通道感知机和局部感知机在训练时是并行的,都使用
首先,假设FC核为
又因为对于任意FC核
所以可以寻找一个FC核
以替换公式(1)中的卷积操作。
因为卷积操作可以被看作在空间位置上带有共享权重的稀疏FC,所以对于任意
下述方法即为寻找
首先,根据“基础公式表示”的FC公式,一个核为
此时引入一个Identity矩阵
同时为了纠正张量尺寸,添加Reshape,有
可以注意到
因此,综合公式(4)、(6)、(7),核
根据上述过程,总结一下就是一个卷积核等效的FC核是对Identity矩阵进行卷积和适当Reshape的结果,且该过程可微。
RepMLPNet
RepMLPBlock Components
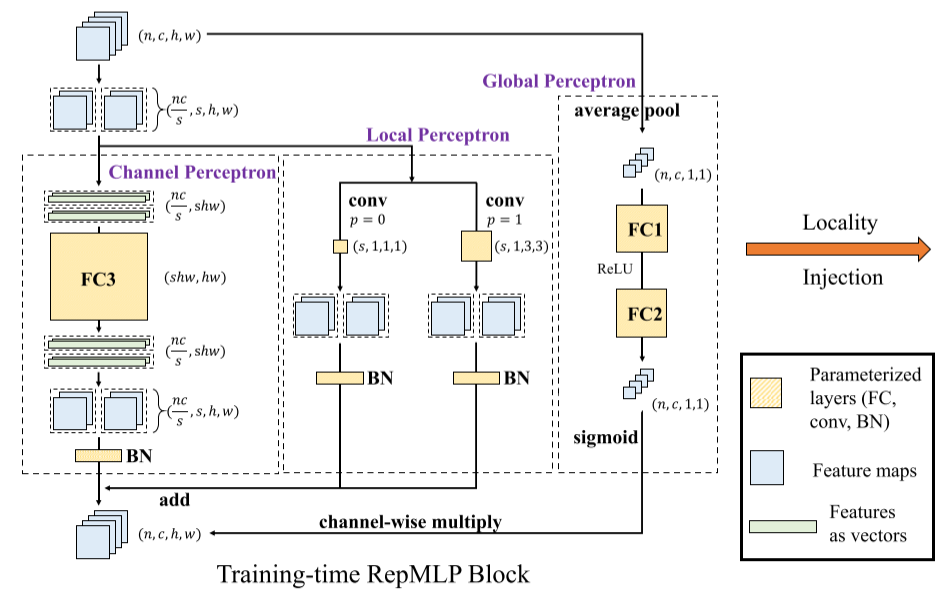
全局感知机:输入维度
经过AvgPool后变为向量 然后经过两个FC层。 通道感知机:如果FC层的输入输出通道相等,那么常规的FC层会产生
个参数,带来很大的参数量。一个比较自然的想法是参照深度卷积,对每个通道做FC操作,因此只需要计算 个通道的FC,即参数量为 。但是该参数量仍然过大,并且这样做会丢失通道之间的依赖关系,因此本文采用分组共享参数的方式构建“Set-Sharing FC”层。其中,对于输入张量,分为 个Set,每组的多通道共享权重集合,因此参数量减少为 。如图2所示, ,相当于将输入的4通道划分为2组,每个组有自己的权重集合。 其具体计算过程为:因为划分为
组,所以有 个通道,考虑batch size则有 个维度为 的张量,即 。将 个张量分别Flatten,得到维度为 的FC输入张量,然后再对每个张量做FC操作,因此FC操作的参数量为 。但是该方法与参照深度卷积的FC操作相比并不能减少计算量。实际操作时,“Set-Sharing FC”将 Reshape为 然后使用1x1卷积进行计算。 局部感知机:其中使用的卷积为深度卷积。
通过Locality Injection将局部感知机融合进通道感知机的过程:
首先明确局部感知机包含一个卷积操作和一次Batch Normalization,其中
为卷积核, 分别为BN操作中的均值、标准差、Scaling因子与bias。所以根据BN计算公式,有: 假设存在
和 ,则公式(9)可简写为: 因此,通过公式(8)可以转换每个卷积操作,产生FC核并叠加到通道感知机中。
分层架构设计
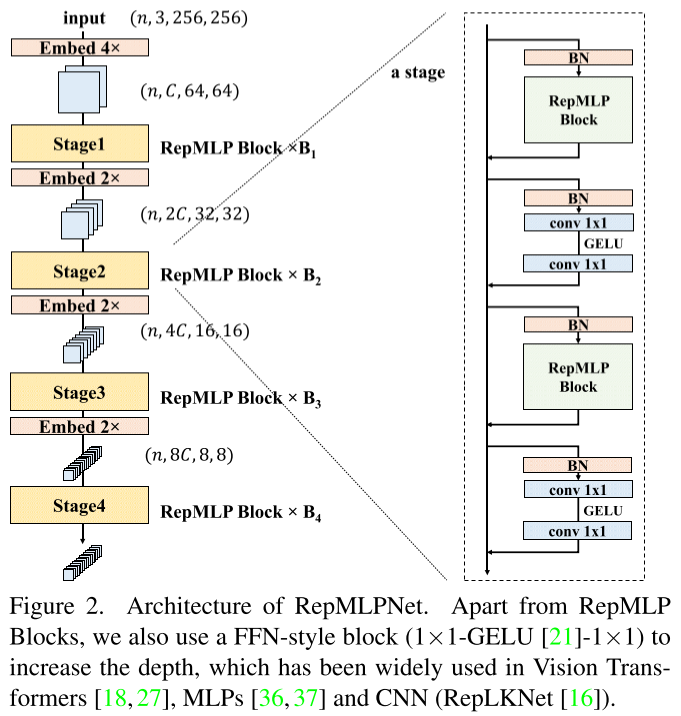
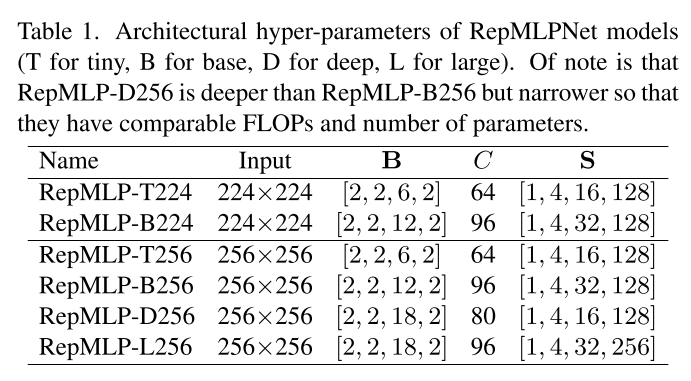
与常规MLP模型的初始大幅降采样后使用小Size计算不同,文中的模型采用卷积网络中常见的分层设计。对于输入图片,采用一个4x4且Stride=4的卷积进行4倍下采样,对于后面的每个阶段,采用Embedding层减半尺寸并加倍通道数。网络规模如下表所示:
实验与结果
图像分类
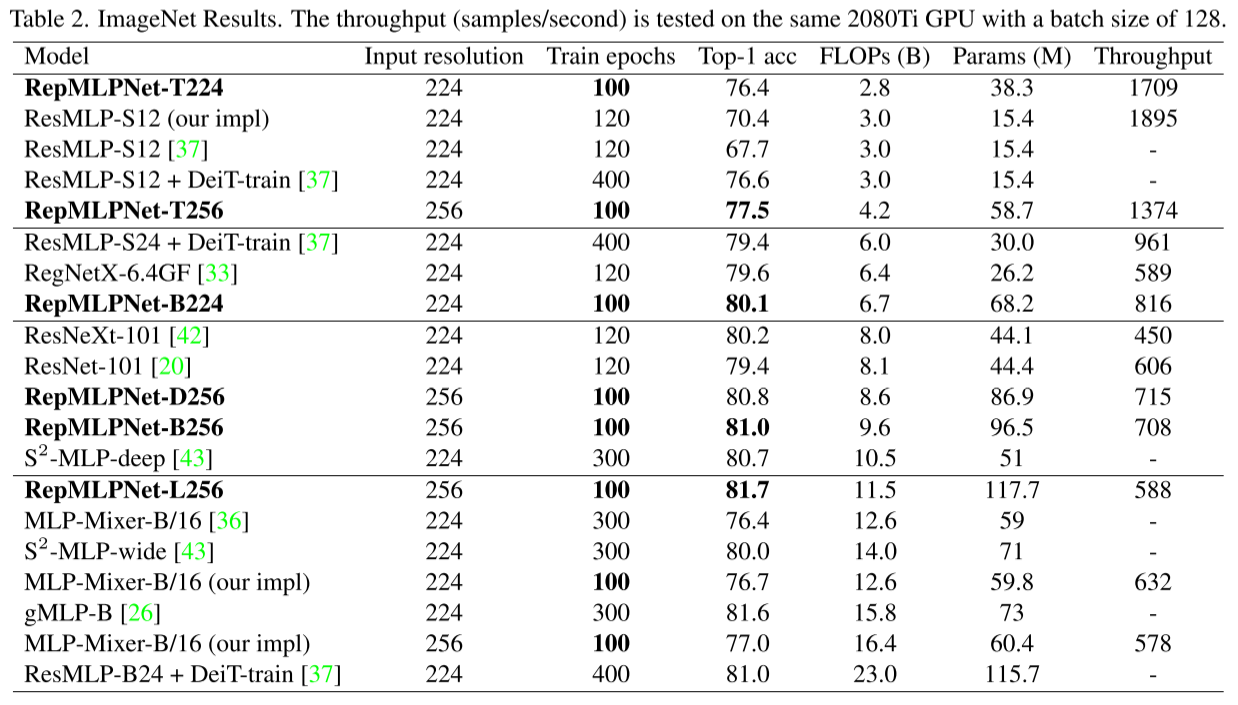
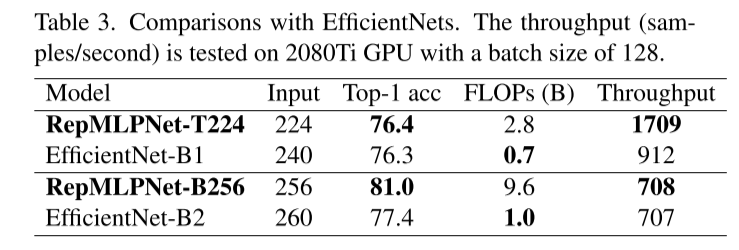
在相同的设置下,RepMLPNetT256在精度上比MLP-Mixer高出0.5%,而前者的FLOPs只有后者的1/4。在简单的训练方法下,ResMLP和MLP-Mixer明显下降,例如,在没有300个epoch DeiT式训练的情况下,ResMLP-S12的准确性下降了8.9%(76.6%→67.7%)。在FLOPs相当的情况下,MLP比CNN快,例如,RepMLPNet-D256的FLOPs比ResNeXt-101高,但运行速度是后者的1.6倍。
语义分割

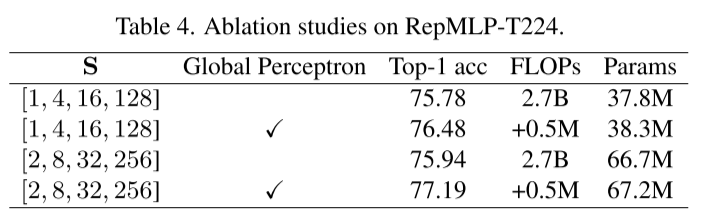
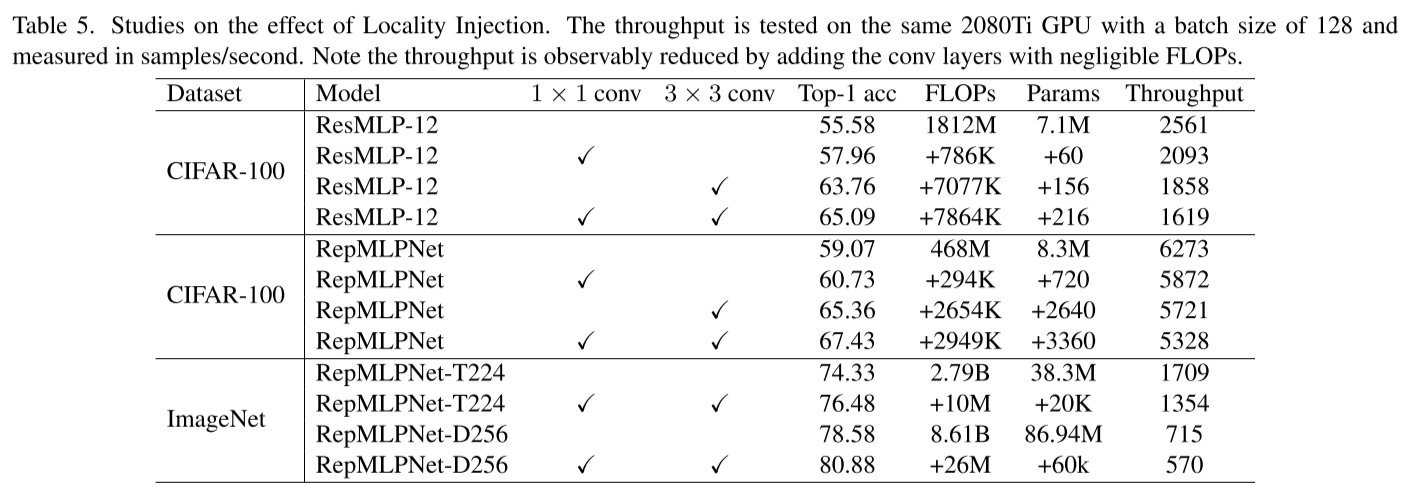
消融实验