- Sucheng Ren,Daquan Zhou,Shengfeng He,Jiashi Feng,Xinchao Wang
- National University of Singapore
- South China University of Technology
- ByteDance Inc.
- CVPR2022 Oral
- Code
背景


传统ViT通过将图片切分为Patch后产生对应的Token然后渐进式的通过全局注意力提取Token特征,这种方法虽然能处理特征的长程依赖关系但是过多的Token会导致在处理复杂的全局关系时丢失细小物体的特征,并且当Token较多时,网络的参数量与计算量会进一步上升。例如上图中天花板的灯在基于ViT的PVT中并没有得到很好的注意,而文中提出的网络结构能够更好地关注细小物体的特征。
Method
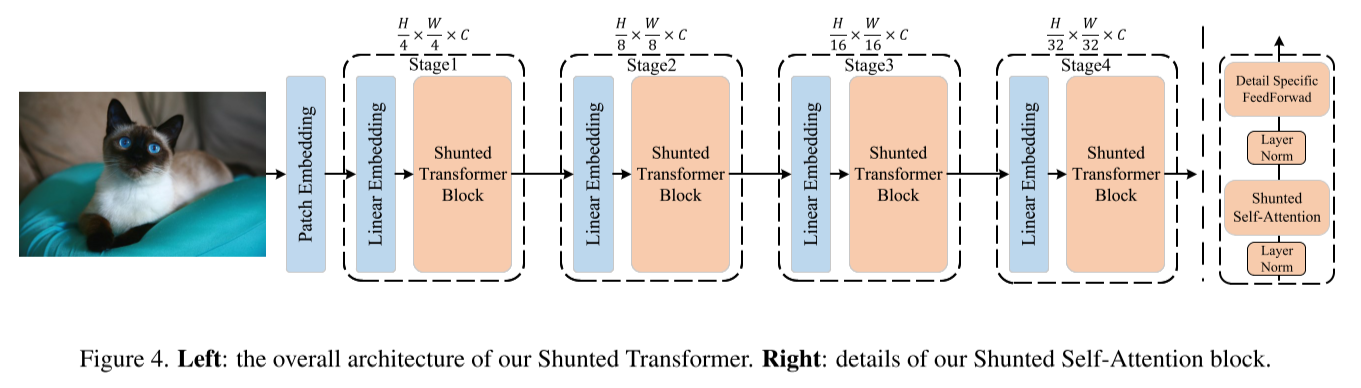
本文总体架构与ViT类似,均采用4阶段模式,辅以Patch Embedding、Linear Embedding操作,每个阶段进行一次下采样减小特征图分辨率并将通道数翻倍。
Shunted Transformer Block
Shunted Self-Attention
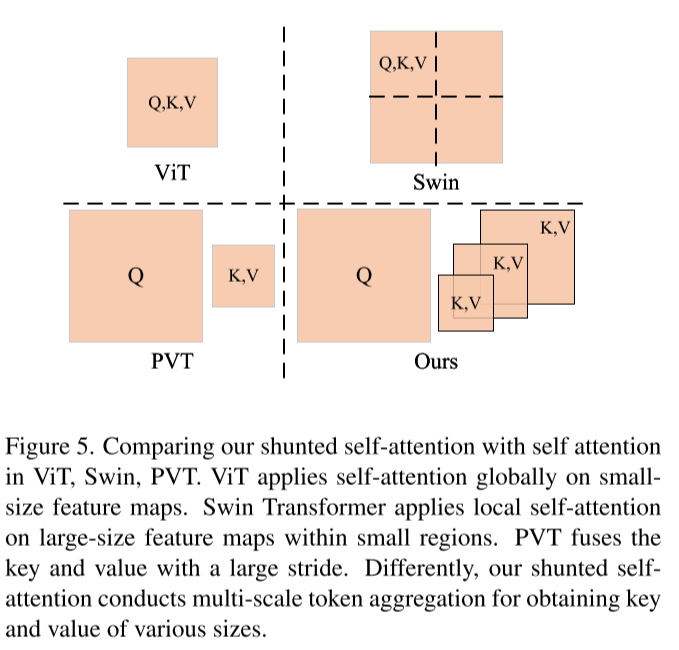
与ViT一样,先将输入序列
其中
通过上述公式可知,当
Detail-specific Feedforward Layers
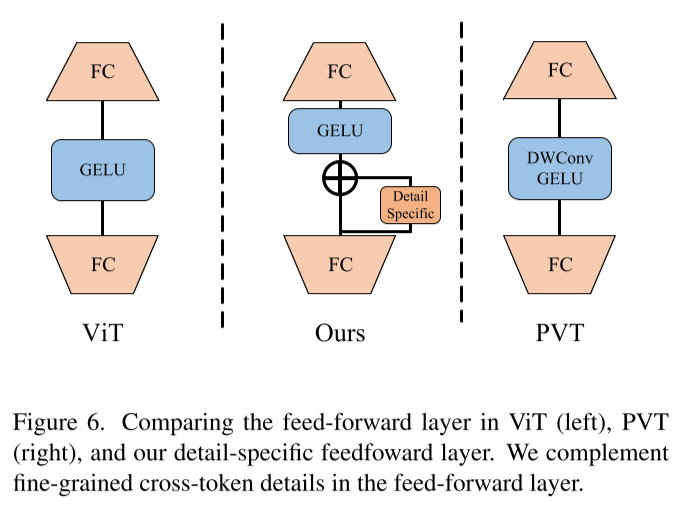
为了进一步补充局部信息,本文的网络在前馈层添加一个Detail Specific模块,因此该网络的前馈层的表述公式为:
其中,
Patch Embedding
论文Scaled ReLU Matters for Training Vision Transformers表明在Patch Embedding阶段使用卷积操作可以得到高质量Token,其效果要比使用单个大Stride的无重叠卷积效果更优秀。
本文中使用两个卷积层和一个Projection层作为Patch Embedding,第一个卷积层为Stride=2的7x7卷积,第二个卷积层为Stride=1的3x3卷积,最终通过一个Stride=2的无重叠Projection层来产生长度为
Architecture Details and Variants
网络的输入为

实验与结果
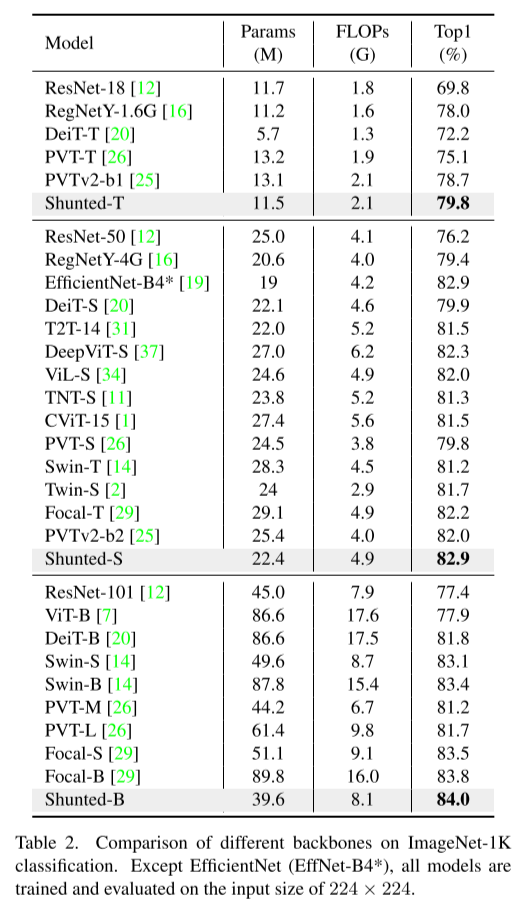
ImageNet-1K 图像分类
COCO 2017 目标检测
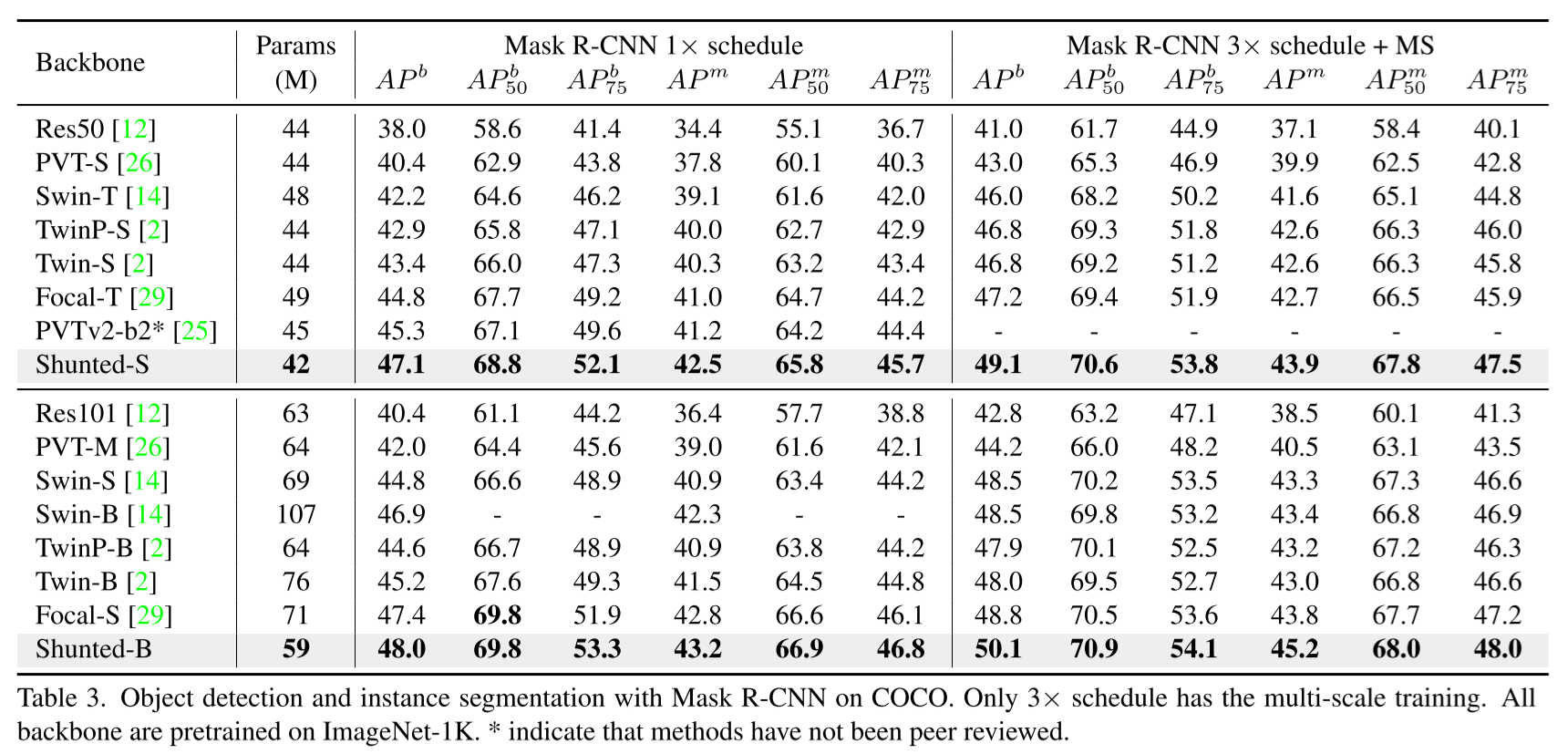
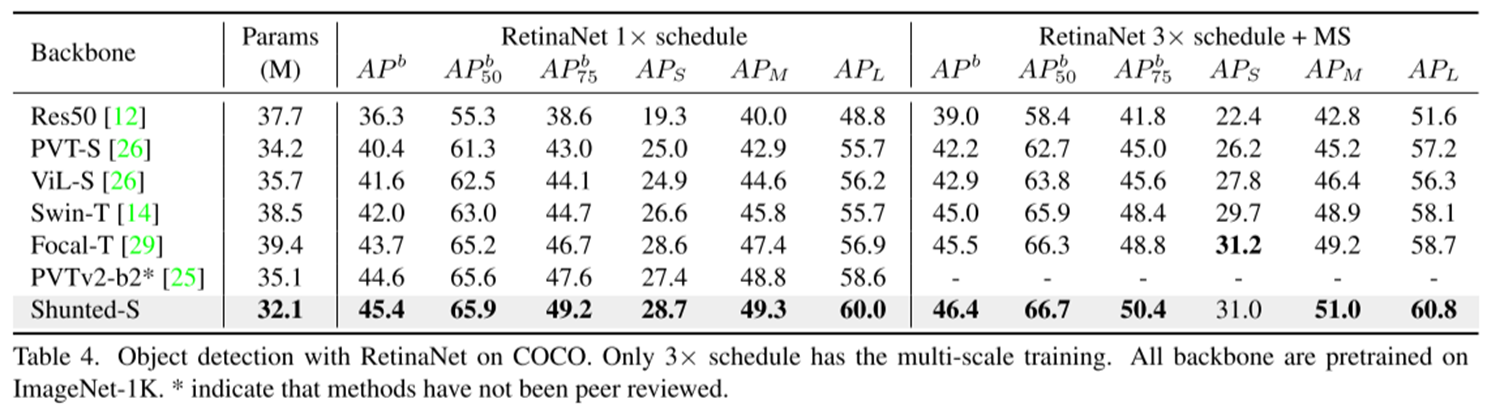
1xSchedule(12 epochs)的fine-tuning阶段将输入图的短边resize为800px,长边不大于1333px;而3xSchedule(36 epochs)的fine-tuning阶段采取多尺度训练策略,将较短的尺寸调整到480至800之间。
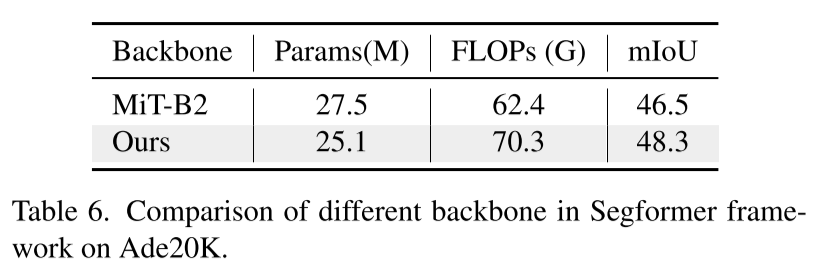
ADK20K 语义分割
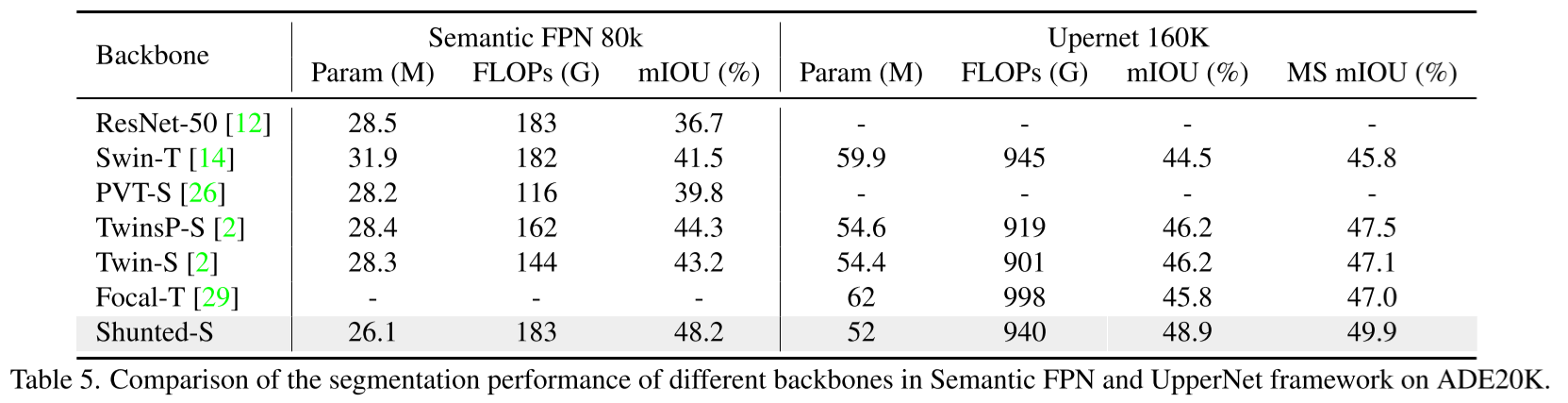
下表为与使用MiT Backbone的SegFormer框架的对比:
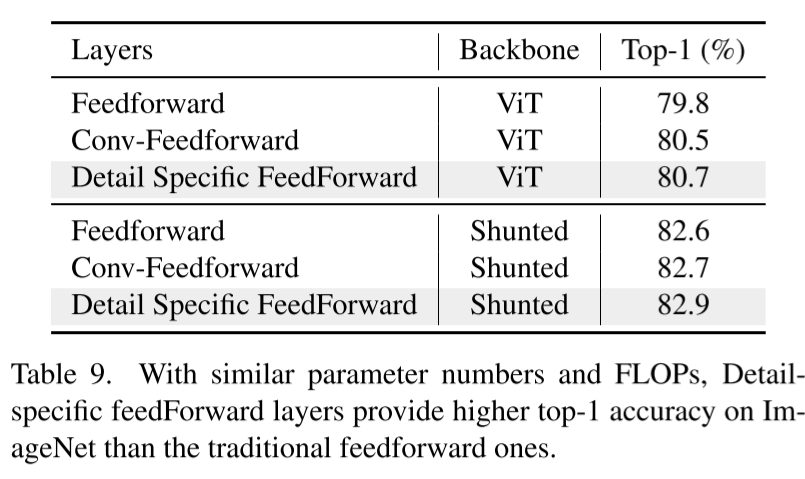
消融实验
Patch Embedding
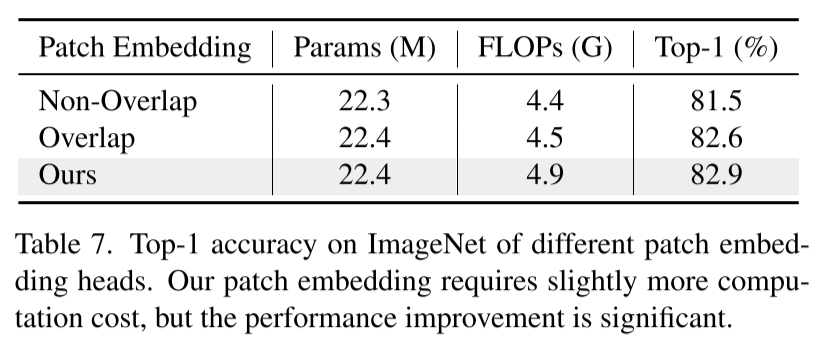
其中Non-Overlap指ViT中使用的策略,而Overlap为Swin和PVT的Embedding策略。
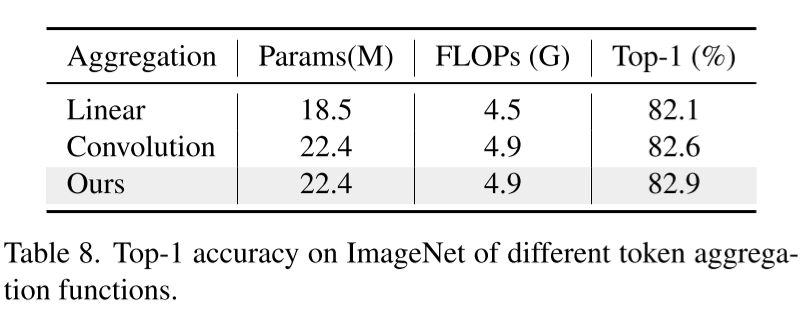
Token Aggregation Function
Detail-specific Feed-Forward