- Weihao Yu,Mi Luo,Pan Zhou,Chenyang Si,Yichen Zhou,Xinchao Wang,Jiashi Feng,Shuicheng Yan
- Sea AI Lab
- National University of Singapore
- CVPR2022 Oral
概述
如下图所示,视觉Transformer包含两个子残差块,第一个一般为Token Mixer模块(诸如MHSA、Spatial MLP等)用于长程特征提取融合,第二个一般为两层全连接层组成的MLP(其中第二层的长度比第一层大2倍/4倍)。
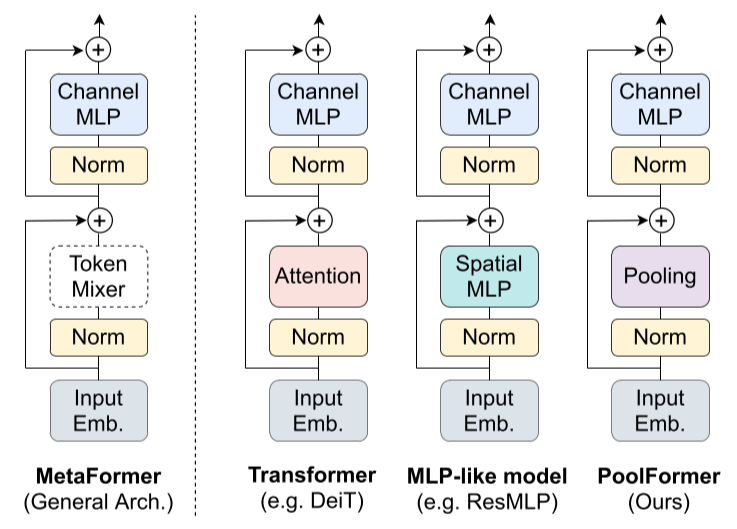
因为通过最近的论文发现传统Transformer的Token Mixer所使用的MHSA更换为Spatial MLP或者傅里叶变换块后仍然能维持很优秀的效果,因此本文对该结构进行了抽象,并且通过实验证明了:相比Token Mixer,整体的Transformer结构(即MetaFormer)才是最重要的。除此之外,本文也就该理念提出了一个将Token Mixer更换为AvgPool的更简单的模型,即PoolFormer,其在ImageNet分类、ADE20K语义分割和COCO目标检测数据集上均能以更少的参数量和更低的MAC(Memory Access Cost)取得与其他Transformer齐平甚至更高的水平。
Method
首先,提出了一个针对传统视觉Transformer Block的结构抽象,其公式如下:
本文针对该抽象提出了一个自己的实现,即Token Mixer使用简单的且无可学习参数的AvgPool,构成PoolFormer Block,PyTorch代码实现如下:
import torch.nn as nn
class Pooling(nn.Module):
def __init__(self, pool_size=3):
super().__init__()
self.pool = nn.AvgPool2d(
pool_size, stride=1,
padding=pool_size//2,
count_include_pad=False,
)
def forward(self, x):
"""
[B, C, H, W] = x.shape
因为TokenMixer之外有一个残差连接,所以此处需要减去该连接。
"""
return self.pool(x) - xAvgPool的stride=1,因此其本身具有一定的特征聚合能力,并且由于自身并没有可学习参数,所以相对于Self-Attention和Spatial MLP等机制,PoolFormer占用显存更少,可以处理非常长的Token序列。完整网络结构如下图所示:
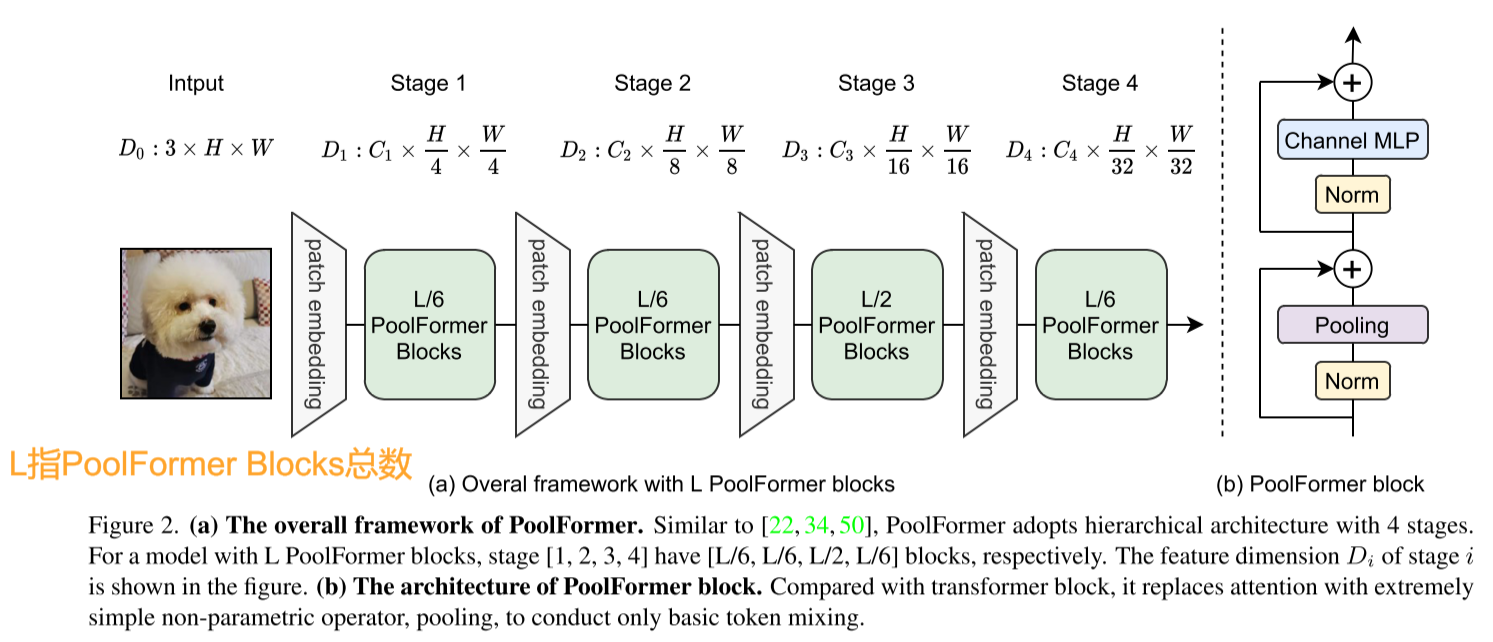
对于Small网络结构,Embedding维度对应至4阶段分别为64、128、320、512;而对于Medium网络结构,Embedding维度分别为96、192、384、768。
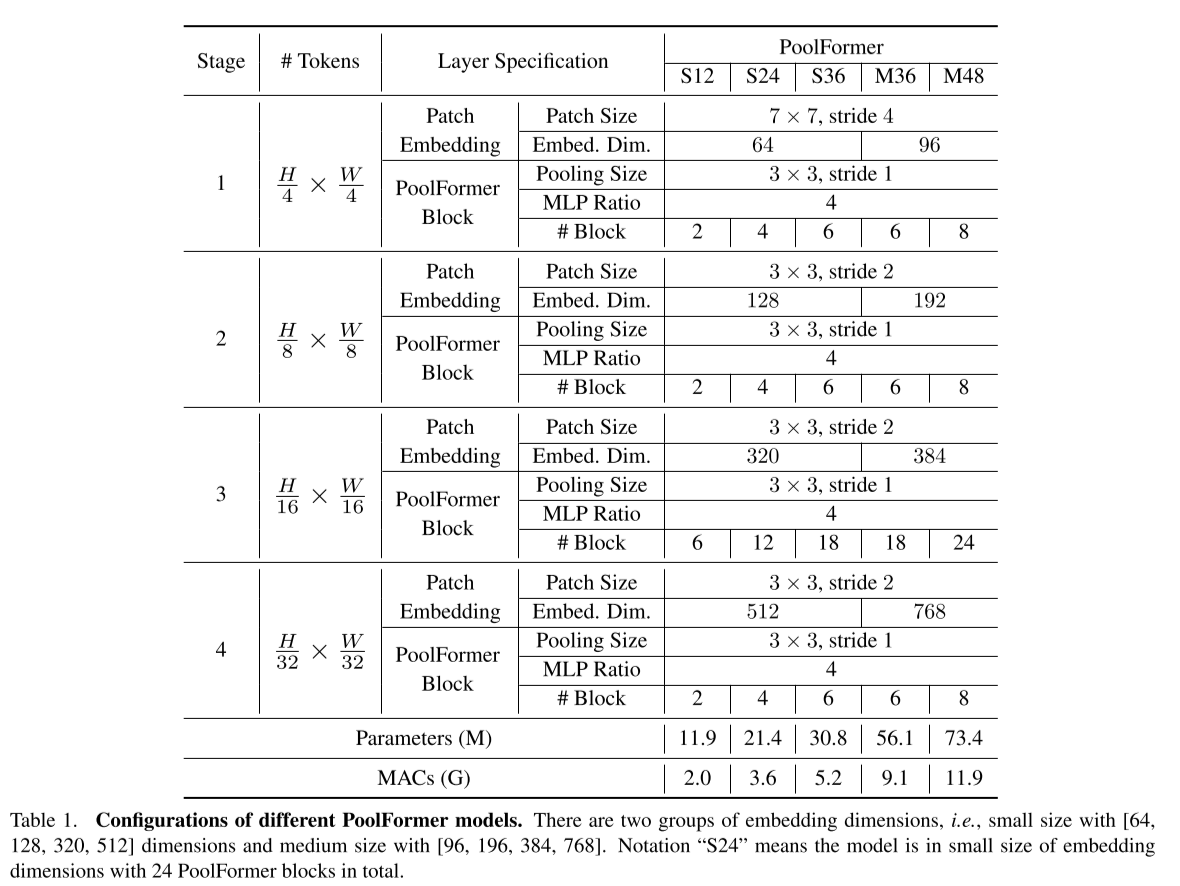
PoolFormer网络架构的几种配置如下所示:
实验
图像分类任务
数据集使用ImageNet-1K,其中包含1.3M张训练图片和5K张验证图片。
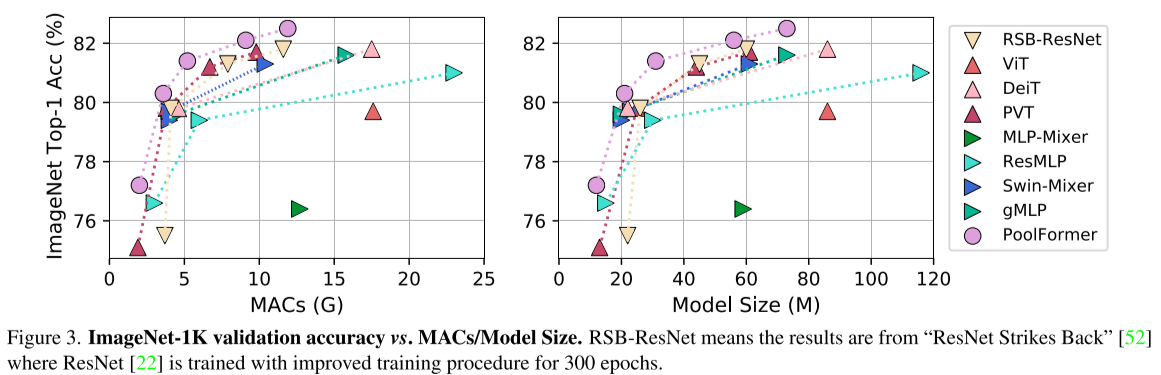
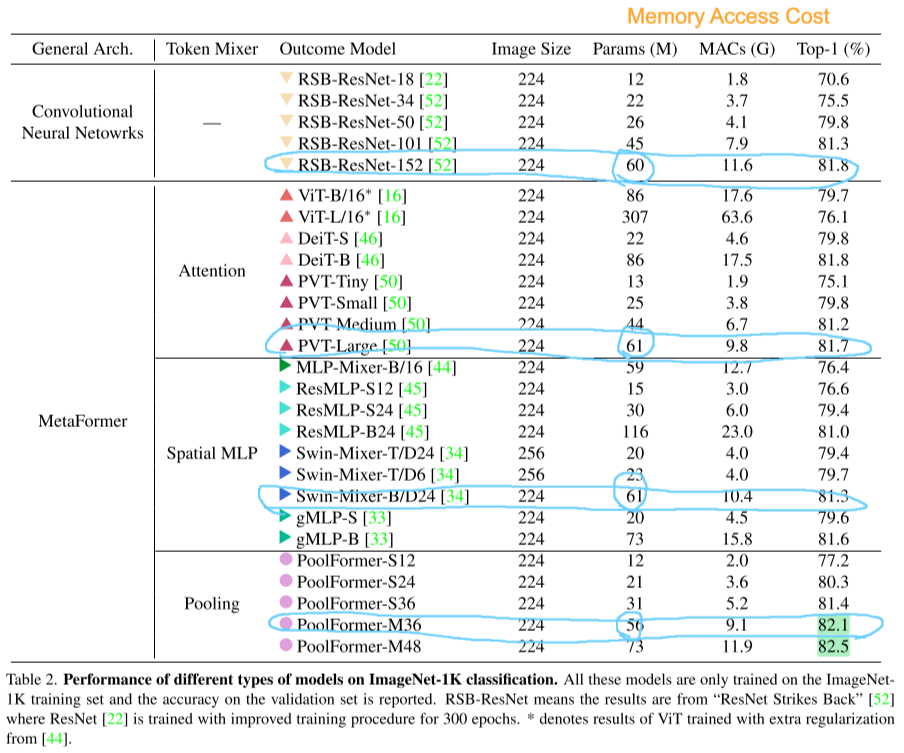
从表中可以看出PoolFormer与使用卷积、SA或Spatial MLP的网络相比,可以在相同甚至更少的参数量的前提下达到更好的效果,并且MAC也更低。
目标检测任务
数据集使用COCO,包含118K张训练图片和5K张验证图片,PoolFormer作为Backbone应用在RetinaNet或者Mask R-CNN中。
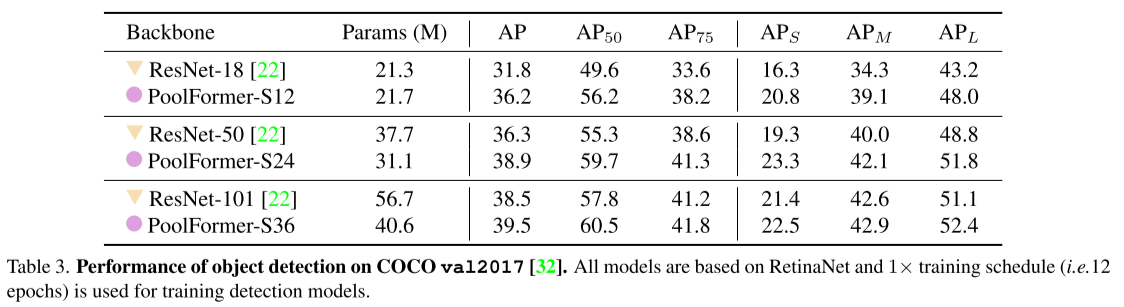
表中数据表明应用PoolFormer Backbone的RetinaNet可以以更少的参数量在AP上击败以ResNet为Backbone的RetinaNet。
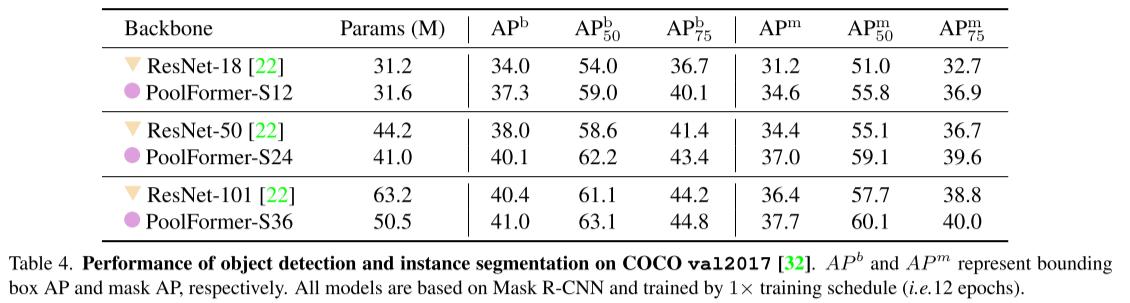
表中数据表明应用PoolFormer Backbone的Mask R-CNN可以以更少的参数量在AP上击败以ResNet为Backbone的Mask R-CNN。
语义分割任务
该任务使用ADE20K数据集,其中训练图片20K张,验证图片2K张。
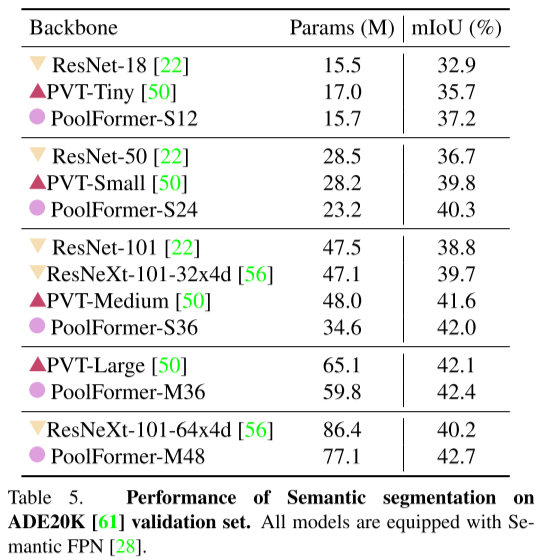
实验表明以PoolFormer为Backbone的Semantic FPN网络用更少的参数量达成了比PVT、ResNeXt、ResNet更好的分割精度。
消融实验
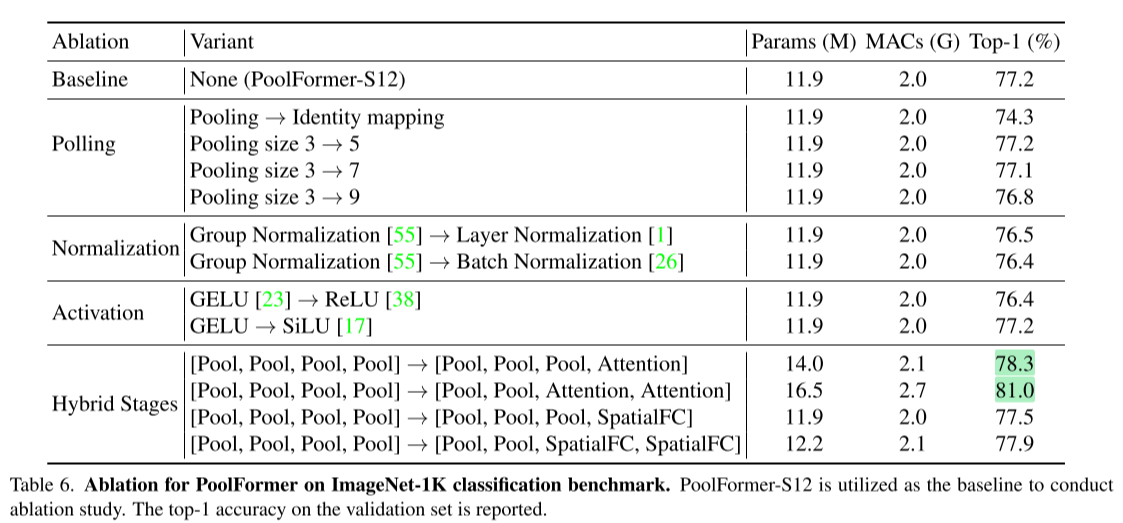
对于Hybrid Stages:由于pool操作可以处理较长的序列信息而SA/Spatial MLP能够捕获全局信息,因此使用混合架构,即先使用PoolFormer处理长序列,随着靠后的Stage的序列长度缩短,改为使用Spatial FC作为Token Mixer,从表中可以看到该方法稍微增加了参数量但也带来了一定的性能提升。