- Pengyang Wang,Yanjie Fu,Hui Xiong,Xiaolin Li
- Missouri Univ. of Sci. and Tech.
- Rutgers University
- Nanjing University
- KDD 2019
背景知识
- 移动用户分析是对用户特定移动活动的特征总结。
- 移动用户特征分析是指从移动活动中提取用户的兴趣和行为模式,如购物和通勤。
- 之前的研究可分为:
- 明确的特征提取。通过明确定义并从移动行为数据(如人口统计学、网站点击、移动购买、应用内行为)中提取的内容特征来分析用户。这样的分析方法高度依赖于对全面的用户相关信息的收集。
- 隐性轮廓学习,包括协作方法、潜在因素模型、网络嵌入和深度学习。
- 特别是,协作方法假设同一群体的用户行为相似,因此,共享相似的分析。这类方法受到目标用户的同伴信息稀少的影响。
- 潜在因素模型,如矩阵/张量因子化或基于主题建模的变体,被开发用来将用户资料建模为潜伏因子或分类分布表示。这类方法通过大参数空间的优化来学习用户特征,因此,很容易过度拟合。它高度需要领域知识启发的模型正则化。
- 人类的活动,如购物、上学、工作、吃饭、旅行、娱乐,都是有空间、时间和社会结构的。我们如何确定一个数据结构来更好地描述一个移动用户的活动?传统的方法提取基于内容的特征向量,并不足以解决这个问题。
本文方法
方法描述
我们知道,一个网页的点击率在很大程度上取决于网页内容和网页结构。同样,如果我们把一个移动用户看作是一个网页,那么用户的活动就可以看作是网页内容,而用户的活动转换模式就可以看作是网页结构。图被广泛用于描述结构性和关系性的知识。一个移动用户的资料确实是一个固有的相互联系的活动组成,并且可以很容易地被建模为一个图。
我们建议构建一个用户活动图来描述每个移动用户,其中顶点是活动类型(即POI类别),边是活动(POI类别)之间的转换频率。通过这种方式,我们将移动用户分析重新表述为从用户活动图中学习用户的深度表征问题。
在研究了许多用户活动图之后,我们发现了另一种重要的结构信息,我们称之为子结构。子结构指的是具有特定拓扑结构的子图。这种子结构确实表明了移动用户独特的个性化活动模式,并暗示了用户的社会属性和偏好。例如,年轻人喜欢在工作综合体、餐馆和电影院之间中转,而企业家喜欢在商业广场之间中转。
在本文中,我们重点关注用户活动图的两个子结构:高频顶点和环。
例子:
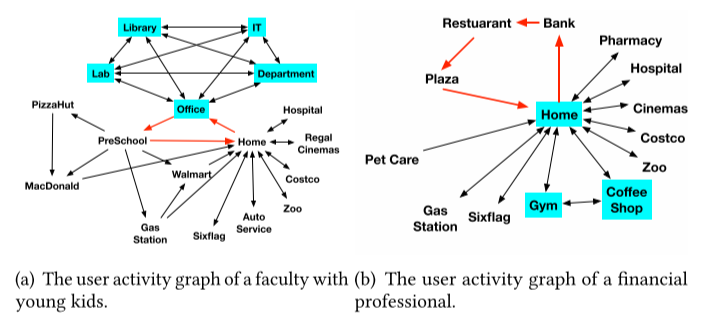
图1显示了两个用户活动图的例子,它们是从用户的移动签到事件集中提取的
{<事件ID,用户ID,日期,POI类别,经度,纬度> }。红色环显示了用户在工作日中经常在不同的POI类别之间转换,青色的独立顶点是该用户在工作期间经常访问的。不同的用户从他们的活动图中显示出不同的子结构。显然,图1(a) 显示了一个有小孩的教师的活动图,其中用户在家里、办公室和幼儿园之间转换,并在工作期间经常访问与大学有关的POI类别;而图1(b) 显示了一个金融专业人士的活动图,其中用户在家里、商业广场和餐馆之间转换,并在工作后经常访问健身房和咖啡馆。
如何将子结构模式整合到用户活动图的表示学习中?我们非常需要一个统一的学习框架来对整个图和子结构信息共同建模。
现有方法的一些问题:一个直观的方法是使用Embedding技术,例如自动编码器,来学习整个图的表示。然后,子结构信息被表述为优化目标的正则化项。然而,如图1所示,不同用户的活动子结构具有不同的拓扑结构(高频顶点,环);这些用户的活动子结构动态地分布在图的不同位置。损失函数中的正则化项无法解决训练中的这些挑战(不同的拓扑结构和分布)。
解决方法:** 生成式对抗网络的出现为解决这一问题提供了巨大的潜力。我们建议将子结构的整合转化为对抗性子结构学习范式。这个范式包括一个自动编码器,用于保留整个图的结构;一个子结构检测器,用于检测图中的子结构;一个对抗训练器,用于通过对抗性攻击纳入子结构的正则化。** 所提出的对抗性子结构学习范式似乎可以从战略上解决这个问题。学习范式可以战略性地解决这些挑战。但是,我们后来发现,如果我们使用传统的子图检测算法(例如,DFS)来作为检测器, 这些检测算法通常是不可微的,因此无法对梯度就行反向传播。为了解决这个问题,我们建议预先训练一个卷积神经网络来捕捉子结构的模式,以接近传统的不可微的子结构算法。
在本文中,我们开发了一个用于移动用户分析的对抗性子结构学习框架。
贡献如下:
- 我们创建用户活动图来描述移动用户的特征、模式和偏好。
- 我们将移动用户分析重新表述为学习用户活动图的深度表示的问题。
- 我们确定了另一个结构信息:用户活动图中的子结构,并开发了一个对抗性的子结构学习范式,包括一个自动编码器、一个检测器和一个对抗性训练器,以保留整个图和子结构信息。
- 我们预先训练了一个卷积神经网络(CNN)来近似于传统的子图检测算法,以解决不可微的问题。
- 我们将用户分析的结果应用于下一个活动类型的预测,并提出了大量的实验,以证明所提出的方法在现实世界中的增强性能。所提出的方法在真实世界的移动签到数据中的增强性能。
前置知识点
定义1:用户活动图/User Activity Graph 。一个移动用户的活动被表示为一个用户活动图,其中顶点是活动类型(即POI类别),边是POI类别之间的转换频率。图1显示用户活动图可以描述用户活动的行为结构信息。
定义2:整图结构/Structure of the entire graph。给定一个用户活动图
,其中V是顶点集,E是边集,整图结构被定义为整个图的全局拓扑表示。整图结构保留了顶点和边之间的关系。对于移动用户,整图结构可以捕获所有POI类别的一般偏好模式。 定义3:子图结构(子结构)/Structure of the subgraph 。其被定义为子图的拓扑表示,能以用户活动的独特行为模式为特征。在本文中,我们重点关注两种类型的子结构。(1) 高频顶点,其累计访问频率高于预先定义的阈值;(2) 环。具体来说,用户活动图中的高频顶点代表对特定类型活动的个性化偏好;用户活动图中的环代表对闭环连续活动模式的个性化偏好。高频顶点和环都可以暗示用户在日常生活中的独特活动模式。
定义4:问题陈述/Problem Statement 。在本文中,我们研究了利用移动活动数据学习用户特征的问题。我们的目标是自动学习一个分析向量来代表一个用户的活动模式。我们从移动活动数据,即POI签到数据中提取用户活动图,以代表移动用户的活动模式。因此,我们把这个问题表述为一个学习用户活动图的深度表征的任务。虽然用户活动图展示了一个用户的整体活动情况,但用户的独特活动模式通常由活动图的各种子结构所暗示。因此,这项任务是一个共同的目标,即在用户活动图中同时保留整体活动模式和在表征学习中保存用户的子结构模式。
从形式上看,给定一组用户活动图,我们的目标是找到一个映射函数
,该函数将用户活动图x作为输入,并输出用户的矢量表示z,同时遵守整图结构和子结构的保存约束。
框架概览
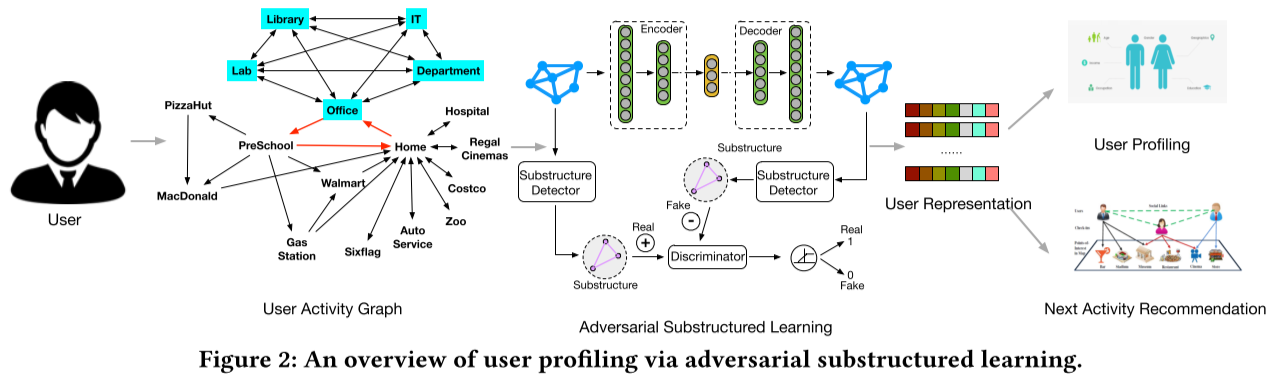
图2显示了我们提出的框架的概况,其中包括以下基本任务:
构建用户活动图来表示移动用户的概况;
开发一个对抗性的子结构学习框架,从用户活动图中学习用户表征;
在下一个活动类型预测的应用中评估学到的用户表征。在第一个任务中,给定用户的移动签到序列,我们为每个用户构建一个用户活动图。在第二个任务中,我们开发了对抗性子结构学习框架,其共同目标是:
对用户活动图的整图结构进行建模;
构建一个可微分的子结构检测器;
利用对抗性训练将子结构正则化纳入表征学习。
在最后一项任务中,我们应用我们提出的方法对移动用户进行剖析,以进行下一个活动类型的预测。
对抗性子结构学习
模型直觉
- 直觉1:整图结构保留。活动图的整图结构代表了用户活动之间的相互作用。这种互动可以是强链接、弱链接或无链接。因此,我们应该保留全局行为模式。
- 直觉2:子结构保留。活动图中有一些独特的子结构,如高频活动和活动过渡环,它们可以独特地描述用户的概况。我们应该保留子结构的行为模式。
- 直觉3:整图结构与子结构的整合 。直观地说,我们可以通过网络Embedding对整个结构进行建模,并通过优化正则化捕获子结构。然而,不同的用户在他们的子结构中可能表现出不同的活动类型、拓扑结构和空间分布。我们需要一个新的学习范式来统一整图结构和子结构。
- 直觉4:可微的子结构检测器。传统的子图检测算法是不可微的。如果这些检测算法被整合到深度学习框架中,就很难应用梯度下降法进行优化。因此,我们需要一个可微分的子结构检测器来接近非可微的检测算法。
总体思路
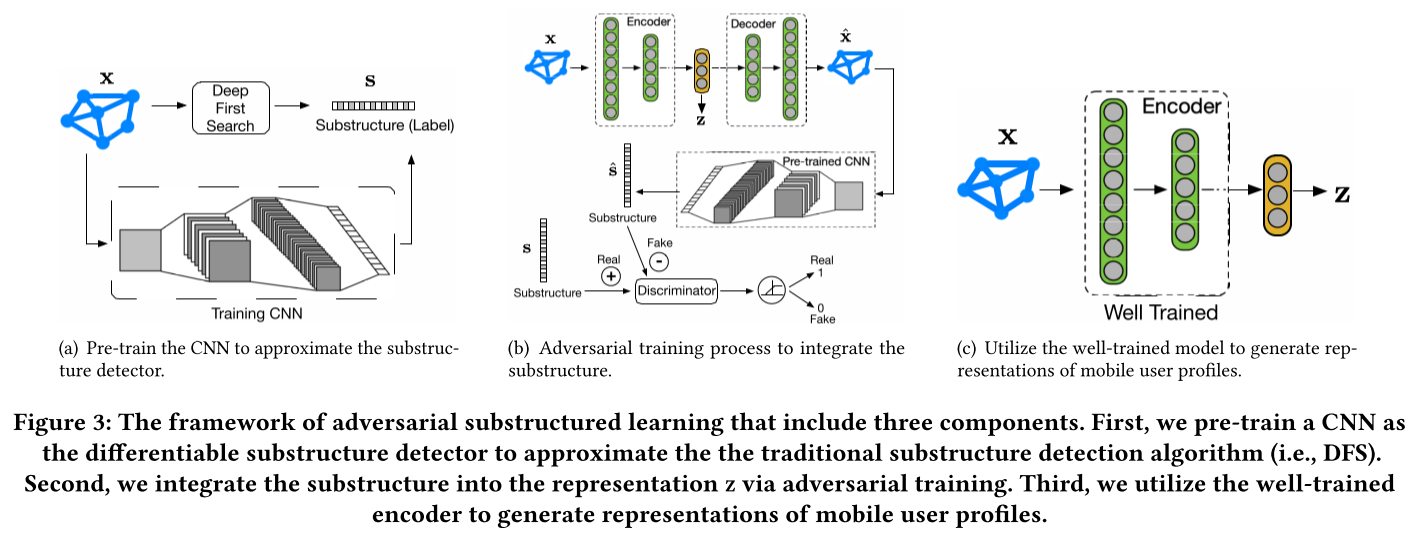
图3显示了我们提出的对抗性子结构学习框架,包括一个深度自动编码器、一个近似的子结构检测器、一个判别器和一个对抗性训练器。自动编码器是为了保留整图结构并推导出图的表示。我们使用传统的子图检测算法来检测子结构标签,然后使用这些标签来预训练一个CNN来接近传统的子图检测算法。鉴别器是对原始图的子结构(真实的子结构集)和重建图的子结构(生成的子结构集)进行分类。对抗训练器通过强制自编码器特别注意保留重建图中的子结构来整合子结构意识,以混淆鉴别器。
保留整图结构
我们利用深度自动编码器,在表征学习中保留用户的全局行为结构。具体来说,该自动编码器包括一个编码步骤和一个解码步骤。编码步骤将用户活动图作为输入,并输出一个用户特征向量。解码步骤使用用户特征向量来重构用户活动图。用户特征向量通过最小化重建损失来捕捉全局行为结构。
形式上,对于给定的第
解码器将Embedding表示
其中,
最小化原图
近似子结构检测器
传统的子结构检测算法,例如,基于DFS的子图检测,是不可微的。神经网络的梯度不能通过反向传播来传递。因此,我们建议使用预先训练好的卷积神经网络(CNN)来近似传统的子结构检测器。
形式上,令
- 生成子结构(label)。使用活动图
作为输入通过 生成对应的真实子结构 作为标注。 - 训练
近似 。 结构包含两组 {Conv, Relu, MaxPooling},其中卷积核为5,池化核为2。令为 的输出,训练目标是最小化损失: 。
最终,我们得到了预先训练好的
通过对抗训练整合子结构信息
图3(b)显示,我们开发了一种对抗性学习策略,包括一个生成器、一个鉴别器和一个对抗性训练器,以整合子结构信息。
生成器:图3(b) 显示,生成器将一个深度自动编码器和一个基于预训练的CNN检测器联系起来。具体来说,我们将预先训练好的CNN连接到解码器的最后一层,这样CNN就将解码器输出的重构图
作为输入。CNN从重建的图中检测并输出一个子结构,用 表示。让G表示生成器,那么映射过程可以表示为: 。 判别器:图3(b)显示,判别器为一个多层感知机
,其中 为其参数, 输出一个概率,表明子结构 来自真实的子结构集 而不是生成的子结构集 的可能性。 对抗训练策略:D的训练是为了最大限度地提高对真实子结构和由G产生的重建子结构的分类精度。G的训练是为了最小化D对由G产生的重建子结构集的分类精度。
形式上,让
表示真实子结构集 的分布, 表示原图集 的分布,对抗训练的minimax函数如下: 特别的,判别器分类准确度为:
生成器损失为:
目标就是最大化损失
和最小化损失 。
解决优化问题
该模型的损失函数包括。(i) 重建损失最小化(公式1);(ii) 鉴别器精度最大化(公式3);以及(iii) 发生器损失最小化(公式4)。其目的是使总体损失
在训练阶段,采用随机梯度下降法来优化,具体来说,先通过下式更新自动编码器:
然后在保持预训练检测器
然后更新判别器:
在测试阶段,图3(c)显示,我们使用子结构感知编码器来学习用户活动图的表示。
讨论
在最近的研究中,有一些与保留结构信息的表示学习有关的工作。例如,Wang等人提出在表征学习中对一阶接近性(即仅由边连接的顶点之间的局部成对相似性)和二阶接近性(即顶点的邻域结构的相似性)进行建模。Yu等人提出通过共同考虑保全位置和全局重建的约束,用对抗性正则化自动编码器来捕获网络结构。这些工作与我们的论文的区别在于,我们的工作旨在将子结构(即子图的结构)整合到整图结构(即整个图的结构)中,而之前的这些工作是对局部结构(即邻居的结构)和全局结构的联合建模。
预测下一个活动类型用户分析
作为一种应用,我们使用所提出的方法对用户活动图进行剖析,并推断出下一个活动类型,以评估其性能。具体来说,我们首先将一个POI类别视为一种活动类型。然后,对下一个活动类型的偏好由POI类别的访问概率分布来表示,标记为
定义:下一步要做什么问题。考虑到用户的历史POI签到记录,我们的目标是通过推断用户在下一天将访问的POI类别的概率来预测用户的下一个活动类型。
具体来说,对每个用户
实验结果
数据描述
表1显示了我们来自两个城市的两个签到数据集的统计数据:纽约和东京。每个数据集包括用户ID,场地ID,场地类别ID,场地类别名称,纬度,经度,和时间。
| 城市 | # Check-ins | # POI类别 | Time Period |
|---|---|---|---|
| 纽约 | 227428 | 251 | 12 April 2012 to 16 February 2013 |
| 东京 | 573703 | 247 | 12 April 2012 to 16 February 2013 |
评估指标
:是指预测用户历史上进行过的下一个预先存在的活动类型的精度。令 表示根据相应的预测访问概率降序排列的Top-K个预测POI类别列表, 表示已访问的POI类别列表, 表示用户集,则 计算公式如下: :是预测用户历史上从未执行过的下一个新活动类型的精度。令 表示用户 在训练集中没有访问过但是在测试集中被访问过的POI类别列表。那么, 计算公式如下:
模型性能
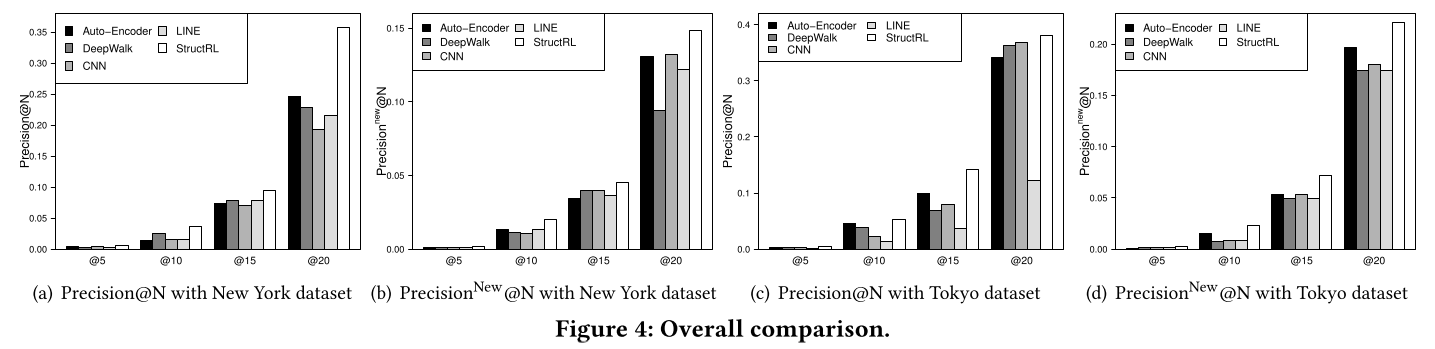
我们在
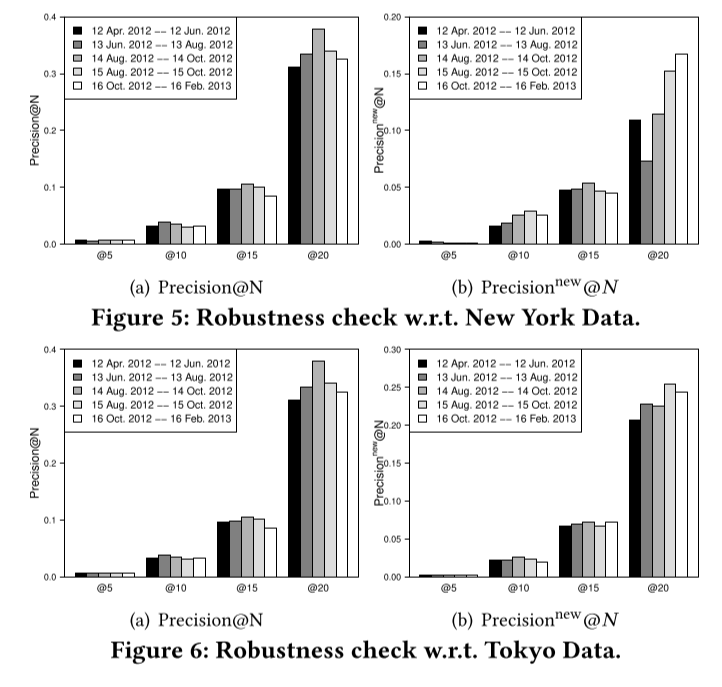
鲁棒性检验
为了进行鲁棒性检验,我们将我们的方法应用于不同的数据子组,以检查我们的表现的差异性。具体来说,我们将数据集平均分成五个时间段,包括(1)2012年4月12日-2012年6月12日,(2)2012年6月13日-2012年8月13日,(3)2012年8月14日-2012年10月14日,(4)2012年8月15日-2012年10月15日,和(5)2012年10月16日-2013年2月16日。我们将每个时间段的最后一天的活动作为预测目标来进行评估。我们对纽约和东京数据集的预测性能进行了
子结构保留的研究
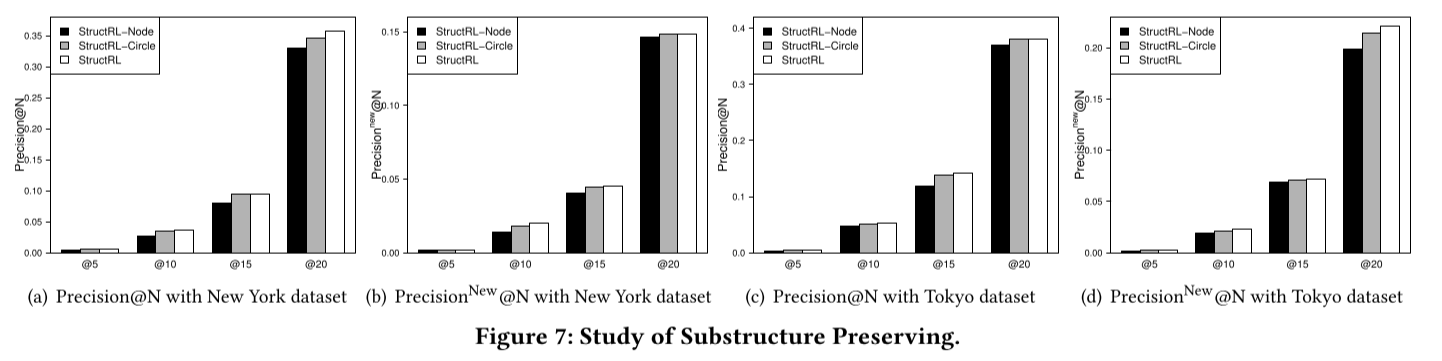
我们引入了两种类型的子结构:独立顶点和环。因此,我们研究这两种不同的子结构类型如何影响我们的方法在使用分析上的表现。具体来说,我们表示(1)StructRL-Node:我们框架的一个变体,只考虑离散顶点的子结构;(2)StructRL-环:我们框架的一个变体,只考虑环的子结构;(3)StructRL:我们提出的方法,考虑两者。
图7显示,StructRL-环的性能总是略微胜过StructRL-Node;换句话说,环的子结构比离散顶点的子结构更有效,可以描述用户的活动模式。环的子结构显示了用户的环活动转换模式,而独立顶点的子结构则显示了用户高度和密集偏好的一些独立POI类别。因此,环的子结构可以描述POI类别之间的相关性,以暗示用户的特定生活方式模式,这比独立顶点的子结构更能提供信息。
训练损失的研究
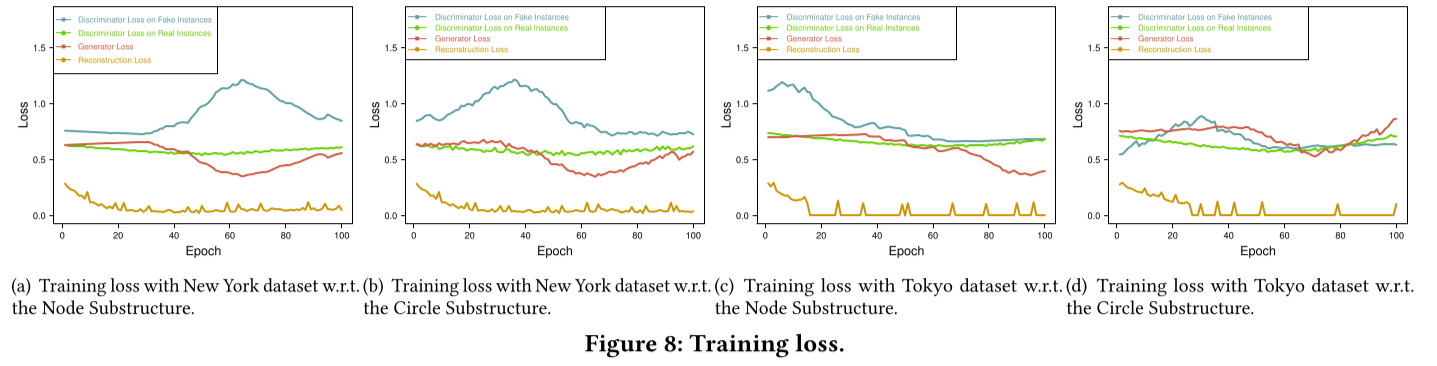
图8显示了我们的方法在不同子结构和不同数据集方面的训练损失。重建损失表明了保留图的全局结构模式的有效性。对抗性训练损失表明将子结构整合到整图结构的学习过程。我们可以看到,在同时进行对抗性训练时,重建损失会收敛。换句话说,将子结构信息整合到全局结构中,有助于训练损失的收敛。
结论
我们研究自动移动用户分析的问题。我们将用户表示为活动图,并将用户分析问题重新表述为从用户活动图中学习表示的任务。在分析了众多用户活动图之后,我们发现保留图的整图结构和子结构至关重要。我们观察到,图中子结构的内容、拓扑和位置可以随不同用户动态变化。我们提出了一种对抗性子结构学习方法,在表示学习中联合建模整图结构和子结构(即暗示移动用户独特的个性化活动模式)。具体来说,我们首先采用自动编码通过最小化图重建损失来对整图结构进行建模。此外,我们预训练了一个CNN来逼近不可微分的子结构检测器,因此子结构检测器可以与自动编码配合使用。此外,我们通过将预训练的CNN附加到自动编码器的最后一层来设计生成器,以生成子结构。此外,我们通过对抗性训练整合子结构意识,联合最小化图重建损失和生成器损失并最大化鉴别器损失。我们还将我们的方法应用于预测下一个活动类型的应用。我们用纽约和东京的数据展示了密集的实验结果,以证明我们方法的有效性。